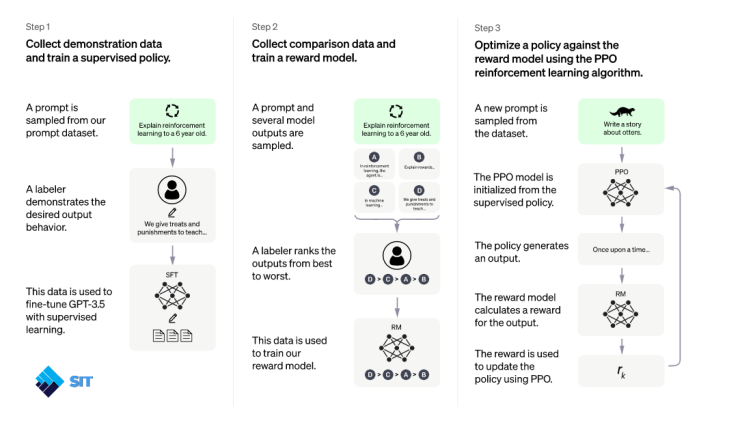
OpenAI ฝึกโมเดลนี้โดยใช้วิธี Reinforcement Learning from Human Feedback (RLHF) โดยเป็นวิธีเดียวกับ InstructGPT แต่มีความแตกต่างเล็กน้อยในการตั้งค่าการรวบรวมข้อมูล ทาง OpenAI ฝึกโมเดลเริ่มต้นโดยใช้การปรับข้อมูลอย่างละเอียดภายใต้การดูแลของ AI เทรนเนอร์ ที่เป็นมนุษย์ซึ่งได้จัดเตรียมบทสนทนาที่มีปฏิสัมพันธ์กันทั้งสองฝ่าย นั่นคือผู้ใช้และผู้ช่วย AI ทาง OpenAI ให้ผู้ฝึก AI เข้าถึงคำแนะนำสำหรับเขียนแบบจำลองเพื่อช่วยทาง OpenAI เขียนคำตอบ
จากนั้นนำบทสนทนาที่ได้มาจัดลำดับคุณภาพแล้วเพื่อให้รางวัล เพื่อสร้างเป็น Rewarding Model แยกอีกชุด แล้วนำ rewarding model ไปปรับแต่งโมเดลหลักด้วยเทคนิค Proximal Policy Optimization (PPO) อีกทีหนึ่ง เพราะจำเป็นต้องรวบรวมข้อมูลเปรียบเทียบ ซึ่งประกอบด้วยแบบจำลองการตอบสนองตั้งแต่สองแบบขึ้นไปที่จัดอันดับตามคุณภาพ ในการรวบรวมข้อมูลนี้ OpenAI นำการสนทนาที่ผู้ฝึกสอน AI มีกับแชทบอท โดยสุ่มเลือกข้อความที่เขียนโดยโมเดล สุ่มตัวอย่างทางเลือกหลาย ๆ ทาง(เราถึงได้เห็นว่ามันสามารถตอบได้หลายรูปแบบมากจากโจทย์เดียวกัน อนาคตจะเก่งขึ้นเรื่อย ๆ เพราะมันคิดได้หลายแนวมากกว่าคนทั่วไป) และให้ผู้ฝึกสอน AI จัดอันดับข้อความเหล่านั้น เมื่อใช้โมเดลการให้รางวัลเหล่านี้ เราสามารถปรับแต่งโมเดลได้อย่างละเอียดโดยใช้ Proximal Policy Optimization และทำกระบวนการนี้ซ้ำหลายครั้ง และกระบวนการเทรนทั้งหมดทำอยู่บน Super Computer ของ Microsoft Azure ที่ร่วมลงทุนใน OpenAI อยู่ก่อนหน้านี้(MS เอาดีด้าน AI มานานแล้วไม่ต่างจาก Google) ChatGPT ได้รับการปรับแต่งอย่างละเอียดจากโมเดลในซีรีส์ GPT-3.5 ซึ่งสิ้นสุดการฝึกอบรมระบบในช่วงต้นปี 2022 รอรุ่นต่อไป GPT-4
ข้อจำกัดของ ChatGPT
บางครั้ง ChatGPT เขียนคำตอบที่ฟังดูน่าเชื่อถือแต่ไม่ถูกต้องเสมอไปหรือไร้สาระก็มี การแก้ไขปัญหานี้เป็นสิ่งที่ท้าทาย เนื่องจาก
1. ในระหว่างการฝึกอบรม RL ขณะนี้ไม่มีแหล่งที่มาของความจริง (แหล่งข้อมูลที่เชื่อถือได้ อารมณ์แบบใครใส่อะไรก็เชื่อ (ผู้ฝึกสอน AI)
2. ฝึกต้นแบบให้ระมัดระวังมากขึ้น ทำให้ปฏิเสธคำถามที่ตอบได้ถูกต้อง
3. การฝึกอบรมภายใต้การดูแลของคนทำให้แบบจำลองเข้าใจผิด เพราะคำตอบในอุดมคติขึ้นอยู่กับสิ่งที่แบบจำลองรู้ มากกว่าสิ่งที่มนุษย์สาธิตให้รับรู้
ChatGPT ไวต่อการปรับแต่งวลีอินพุตหรือพยายามใช้ Command Prompt เดียวกันหลายครั้ง ตัวอย่าง เช่น เมื่อพิจารณาคำถามหนึ่งประโยค แบบจำลองสามารถอ้างว่าไม่ทราบคำตอบ แต่สามารถตอบได้อย่างถูกต้องหากใช้ถ้อยคำใหม่เล็กน้อย(ดูความเกรียน)
โมเดลมักมีรายละเอียดมากเกินไปและใช้บางวลีมากเกินไป เช่น การย้ำว่าเป็นโมเดลภาษาที่ฝึกโดย OpenAI ปัญหาเหล่านี้เกิดจากอคติในข้อมูลการฝึกอบรม (ผู้ฝึกอบรมชอบคำตอบที่ยาวกว่าและดูครอบคลุมมากกว่า ก็จะเอาละเอียดไง 555) และปัญหาการปรับให้เหมาะสมมากเกินไป อาจจะเกินจำเป็น อารมณ์นึกถึง Jarvis แนะนำ Tony แต่แนะนำเยอะไปละ ประมาณไม่ต้องรู้มากก็ได้
ตามหลักการแล้ว โมเดลจะถามคำถามที่ชัดเจนเมื่อผู้ใช้ระบุข้อความค้นหาที่ไม่ชัดเจน แต่โมเดลปัจจุบันของ ChatGPT มักจะเดาว่าผู้ใช้ต้องการอะไร รู้มากไปอีก
แม้ว่าเราจะพยายามทำให้โมเดลปฏิเสธคำขอที่ไม่เหมาะสม แต่บางครั้งโมเดลก็จะตอบสนองต่อคำแนะนำที่เป็นอันตรายหรือแสดงพฤติกรรมที่มีอคติ (นี่คือโจทย์ที่ต้องแก้) OpenAI กำลังใช้ API การกลั่นกรองเพื่อเตือนหรือบล็อกเนื้อหาที่ไม่ปลอดภัยบางประเภท(อันนี้สำคัญ) แต่คาดว่าเนื้อหาดังกล่าวจะมีทั้งผลลบและผลบวกปลอมอยู่ในขณะนี้ OpenAI กระตือรือร้นที่จะรวบรวมความคิดเห็นของผู้ใช้เพื่อช่วยงานที่กำลังดำเนินอยู่และใช้ในการปรับปรุงระบบนี้ ตอนนี้น่าจะมีคนทั่วโลกพยายามไปเล่นกันอยู่ ดีต่อระบบ มันล่มไม่แปลกเพราะยังไม่ได้ออกแบบให้รองรับปริมาณผู้ใช้หลายล้านคน
การปรับใช้ซ้ำ
การเปิดตัวงานวิจัย ChatGPT เป็นขั้นตอนล่าสุดในการปรับใช้ระบบ AI ที่ปลอดภัยและมีประโยชน์มากขึ้นเรื่อยๆ ของ OpenAI บทเรียนมากมายจากการปรับใช้โมเดลก่อนหน้า เช่น GPT-3 และ Codex ได้แจ้งถึงการลดความปลอดภัยที่มีอยู่สำหรับรุ่นนี้ รวมถึงการลดลงอย่างมากในผลลัพธ์ที่เป็นอันตรายและไม่เป็นความจริง(Fake) จากการใช้วิธีใช้อบรมระบบด้วยความคิดเห็นของมนุษย์ (RLHF)
OpenAI ทราบดีว่ายังมีข้อจำกัดมากมายตามที่กล่าวไว้ข้างต้น และกำลังวางแผนที่จะทำการอัปเดตโมเดลเป็นประจำเพื่อปรับปรุงในด้านดังกล่าว และยังหวังว่าด้วยการจัดเตรียมอินเทอร์เฟซที่เข้าถึงได้ให้กับ ChatGPT จะได้รับคำติชมอันมีค่าจากผู้ใช้เกี่ยวกับปัญหาที่ OpenAI ไม่เคยทราบมาก่อน
อันนี้ดีหาเงินได้ เพื่อรับเครดิต API สูงถึง $500
คุณสามารถเลือกที่จะเข้าร่วมการแข่งขันข้อเสนอแนะที่เป็นประโยชน์ให้กับ ChatGPT3
ต้องมีอายุอย่างน้อย 18 ปีจึงจะเข้าร่วมได้ สามารถส่งผลงานผ่านแบบฟอร์มคำติชมที่ลิงก์ในอินเทอร์เฟซ ChatGPT
#ChatGPT #OpenAI #ChatBot #deeplearning #AI #SmartIT #SmartConsult #MSAzure #Cloud #BigData #datamodeling








{kind=link}